Qubic Lab
A 3D Qubic playground for PPO/GAE, MCTS, probes, self-play, report cards, and AlphaZero-style reinforcement-learning experiments.
What it is
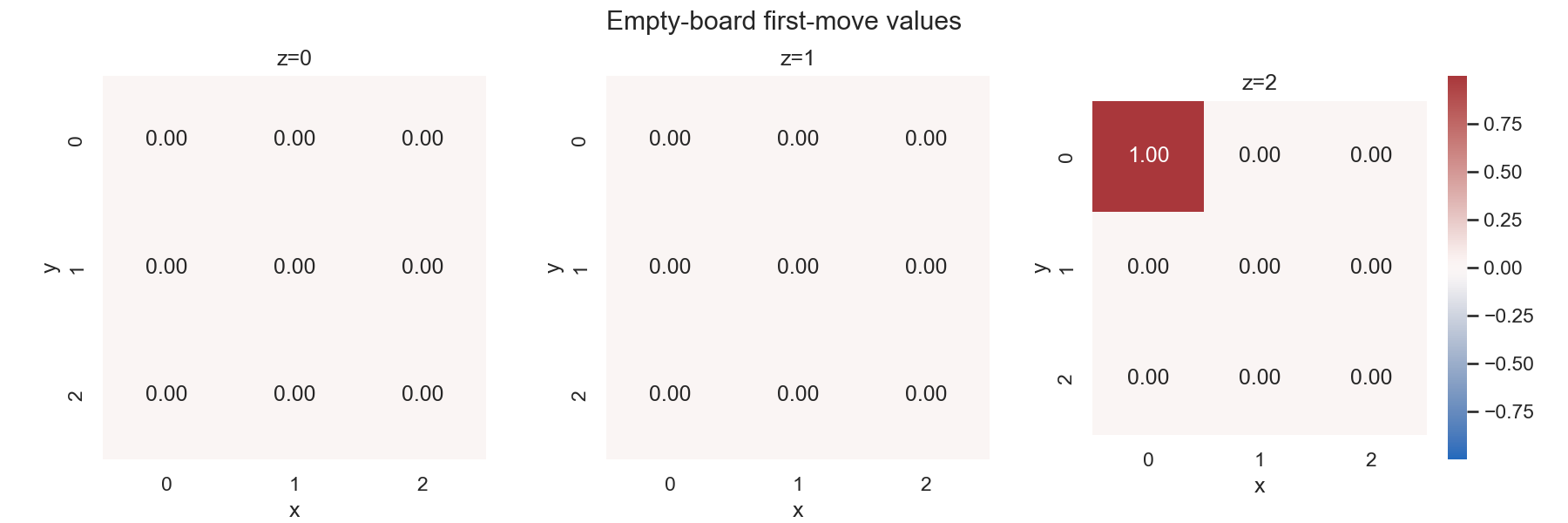
A game-AI lab around Qubic, a 3D tic-tac-toe family that is small enough to inspect but hard enough to expose sparse-reward RL failure modes. The repo includes a rules engine, win-line generation, policy/value models, PPO and GRPO baselines, MCTS opponents, AlphaZero-lite training, saved-run artifacts, and a browser lab for heatmaps, metrics, evaluation, and play.
Why it matters
Qubic is large enough to force real search, credit-assignment, and evaluation choices, but small enough to keep the full state/action encoding and self-play dynamics understandable. The project is designed to make RL claims falsifiable: training curves are paired with fixed evaluation, probe suites for immediate wins/blocks, hard-state replay artifacts, and model report cards.